Abstract
Computer Vision and Pattern Recognition – CVPR 2023
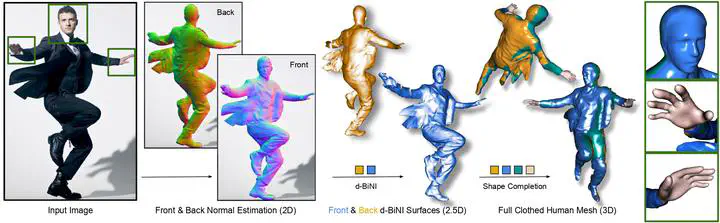
The combination of artist-curated scans, and deep implicit functions (IF), is enabling the creation of detailed, clothed, 3D humans from images. However, existing methods are far from perfect. IF-based methods recover free-form geometry but produce disembodied limbs or degenerate shapes for unseen poses or clothes. To increase robustness for these cases, existing work uses an explicit parametric body model to constrain surface reconstruction, but this limits the recovery of free-form surfaces such as loose clothing that deviates from the body. What we want is a method that combines the best properties of implicit and explicit methods. To this end, we make two key observations:(1) current networks are better at inferring detailed 2D maps than full-3D surfaces, and (2) a parametric model can be seen as a “canvas” for stitching together detailed surface patches. ECON infers high-fidelity 3D humans even in loose clothes and challenging poses, while having realistic faces and fingers. This goes beyond previous methods. Quantitative, evaluation of the CAPE and Renderpeople datasets shows that ECON is more accurate than the state of the art. Perceptual studies also show that ECON’s perceived realism is better by a large margin.
Yuliang Xiu
Co-advising with M. J. Black
Interned as PhD: Ubisoft, Meta (soon)
Next: Assist. Prof. @ Westlake University
Next